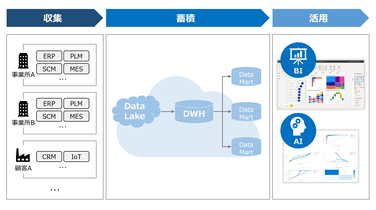
本記事では、昨今のDX・データ活用において重要視されているデータレイクの必要性とそれを実現するためのソリューションについて考えます。
データレイクの必要性とデータウェアハウスとの違い
データレイクは、2010年代に入ってから注目され始めた考え方です。似た言葉として、「データウェアハウス」がありますが、データレイクはデータウェアハウスよりも新しい概念となります。つまり、ビッグデータ時代において、データウェアハウスだけでは解決できない課題が生じたことから、データレイクの必要性が叫ばれるようになりました。
- 課題①:データ種別の多様化
- データウェアハウスはRDBMSをベースとしているため、対象が構造化データに限定されます。よって、取り扱うデータがERPやCRM等のビジネスデータであれば問題ないものの、IoTデータやログデータ、テキストデータなどの半構造化・非構造化データには対応できません。さらに、データウェアハウスに格納するためには、適切な形式へデータを加工するETLが必須であり、そのためのコストがデータ活用を妨げる要因にもなり得ます。
- 課題②:乱立するデータウェアハウス
- データウェアハウスには「活用の目的が存在する」という特徴があります。「使うかどうか分からないデータを"とりあえず"データウェアハウスに貯めておく」といった使い方は一般的ではありません。また、この特徴により、各部門はそれぞれの目的に合わせた、個別のデータウェアハウス(マーケティング部門向け、生産部門向け、品質保証部門向け等)を構築します。よって、「同じデータが複数のデータウェアハウスに存在し、どれがマスタなのか不明」、「毎回必要なデータをデータソースまで取りに行かなければならない」などの問題が生じます。
データレイクは、上記のような課題を解決するために提唱された考え方です。データソースから収集されたデータを加工せずにそのまま保管することで、将来的な活用に備えます。
また、データレイクは「真」のデータを保管する場所「Single Source of Truth(信頼できる唯一の情報源)」として設計されるため、常に最新のマスタデータを保持します。これにより、「どこからデータを取得すれば良いか分からない」という悩みは生じず、効率的なデータ活用に繋げることが可能です。
データレイクとデータウェアハウスの違いを整理すると、下記の表の通りとなります。
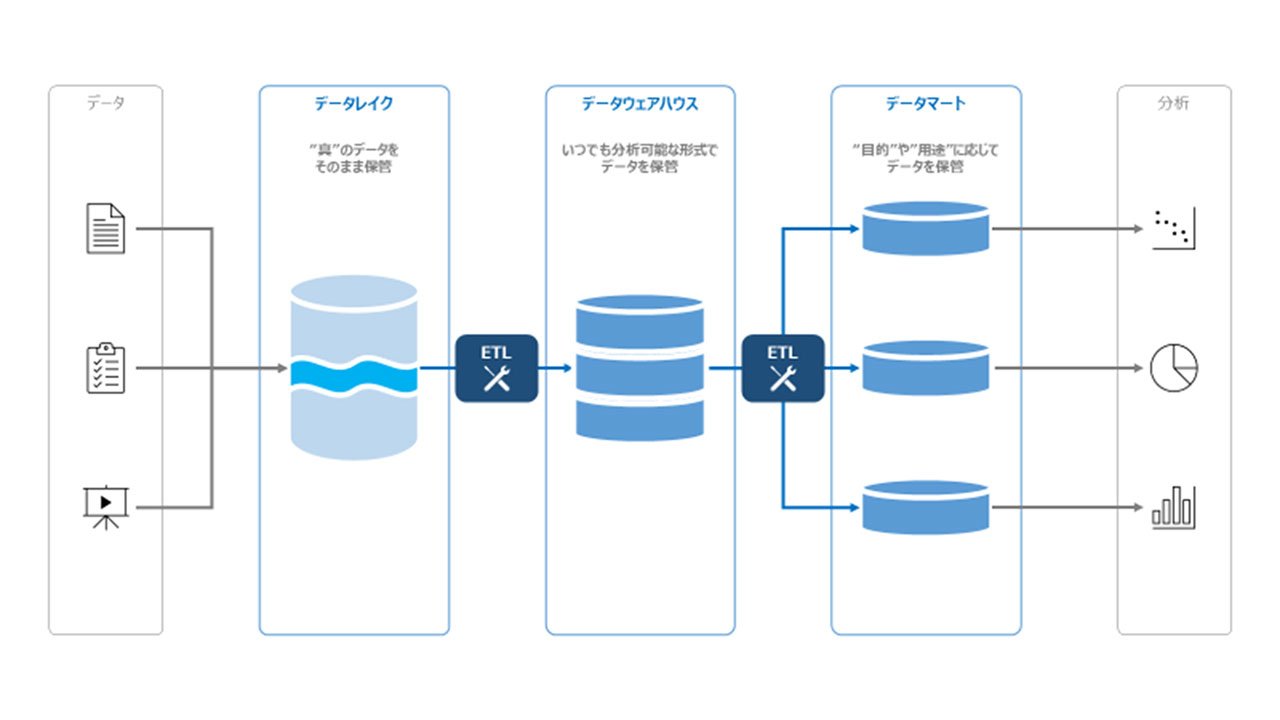
データ分析基盤の概念図
データ分析基盤の構成要素とは?
データレイクはデータ分析基盤の構成要素の1つです。データ分析基盤には、データレイク以外にも多数の構成要素が存在し、そのことがデータ分析基盤の理解を妨げる要因になっています。ここでは、データ分析基盤の代表的な構成要素について紹介します。
- データレイク
- 前述の通り、生データを保管するストレージ。
膨大なデータの保管に長け、安価で使用可能なことが特徴である。
サービス例:Amazon S3, Azure Data Lake Storage Gen2
- データウェアハウス
- 大規模なデータに対して複雑な集計クエリの実行を可能とするデータベース。
分散処理のためのコンピューティングリソースが必要なため、費用としては高価。
サービス例:Snowflake, Amazon Redshift, Azure Synapse Analytics, BigQuery
- データマート
- 使い勝手やパフォーマンスの向上のため、データウェアハウスの一部のデータを切り出したもの。
データウェアハウスのビューやRDBMS、BIの内部データセットなど形式はさまざま。
- ETL
- データを抽出・加工・書き出しするために用いられるツール。
昨今はローコード・ノーコードで直観的に処理(コピー、集計、型変換等)を実装できるツールが増えている。
サービス例:AWS Glue, Azure Data Factory, ASTERIA Warp, DataSpider
- データカタログ
- ガバナンス担保のために用いられるデータの辞書。
データの管理者やリネージ(どこから来たデータなのか)を管理し、データ活用の信頼性を向上させる。
サービス例:Azure Purview, Informatica
- AI
- 機械学習モデルの構築・運用基盤。
データサイエンティストのスキルに依存せず、最適なモデル構築が可能な自動ML機能がトレンドになっている。
サービス例:Amazon SageMaker, Azure Machine Learning, DataRobot
- BI
- データをさまざま軸でグラフィカルに表示し、分析するためのツール。
サービス例:Power BI, Tableau
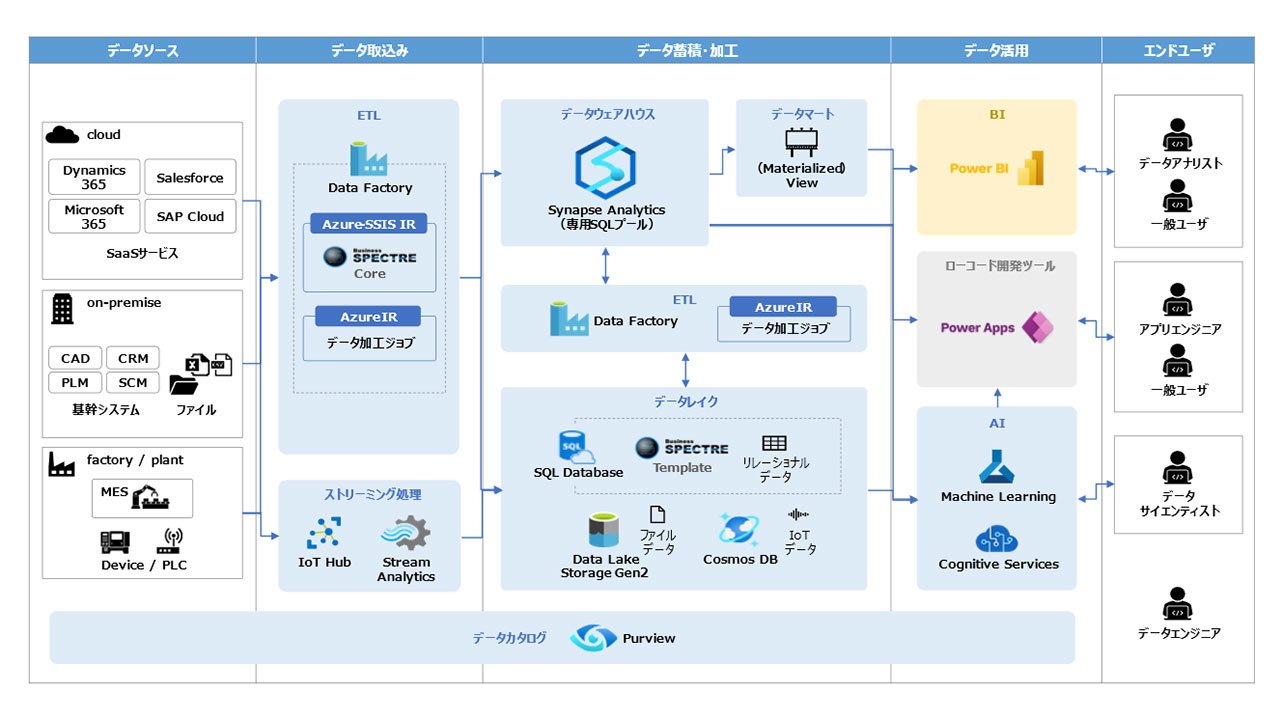
一般的なデータ分析基盤の構成例(Azureの場合)
最新のデータ分析基盤を提供する「Microsoft Fabric」
2023年11月、Microsoft社より最新のデータ分析基盤サービスである「Microsoft Fabric」がリリース(一般提供)されました。Fabricは、従来ほとんど存在しなかった完全SaaS型のデータ分析基盤です。よって、インフラの構築・運用に関わるコストは一切不要であり、ユーザはFabricで提供されるワークスペース上のみで操作を完結できます。また、利用コストは従量課金制となっており、スモールスタートに適した価格体系で提供されます。Fabricの主な特徴は、下記の通りです。
- OneLakeによるデータ一元化
- Fabricで保持するデータは、OneLakeと呼ばれる論理データレイク上にて管理されます。さまざまな形式のデータが全て同じ場所に配置され、各種分析エンジンからアクセス可能です。前述の通り、OneLakeがSingle Source of Truth(信頼できる唯一の情報源)としての役割を果たします。
- 全てのデータ分析のユースケースに対応した機能
- Fabricには、データ分析に関わる全てのユースケース・ワークロードに必要な機能が搭載されています。具体的には、前述の「データ分析基盤の構成要素」がFabric単体で網羅できており、BIまで含め、1つのサービス・GUI上から全ての分析操作が可能です。
- Copilotによる開発支援
- FabricにはCopilot(AIアシスタント)が搭載されています。自然言語による会話形式で分析操作を指示し、データフローやパイプライン、SQL、BIレポート、機会学習モデル等が作成できます。
発表されて間もないFabricですが、電通総研では、リリース以前よりFabricの技術検証を進めてきました。Microsoft社とのリレーションを活かしつつ、データ分析の第一歩を踏み出すためのプロジェクト推進を支援させていただきます。Fabricに関する電通総研の強みは下記の通りです。
- Fabricに関するナレッジ
- Fabricが一般提供となった2023年11月以前より、サービスに関する調査・技術検証を実施しています。得られた知見は社内でのナレッジ化に加え、DENTSU SOKEN Tech Blog.等にも公開していますので、ご興味がございましたら、是非ご覧ください。
- 豊富なPoCメニュー
- FabricのPoCを実施する上では、ユースケースの選定やコストの算出など、いくつかの検討プロセスの実施が必要となります。電通総研では、そうしたプロセスをいくつかのテンプレートとして整理した上でご提供しており、本格的な開発に向けた課題の洗い出しやアクションプランの検討など、上流工程のコンサルティングから支援させていただきます。
- Microsoft社との強固なパートナーシップ
- データ分析基盤(Analytics領域)をはじめとした各種技術領域について、Microsoft社とのプロジェクト推進実績を有しています。特にAI領域では、「Microsoft Azure の AI および Machine Learning」Specialization認定を日本企業として初めて取得しており、Data×AI領域における協業を加速しています。
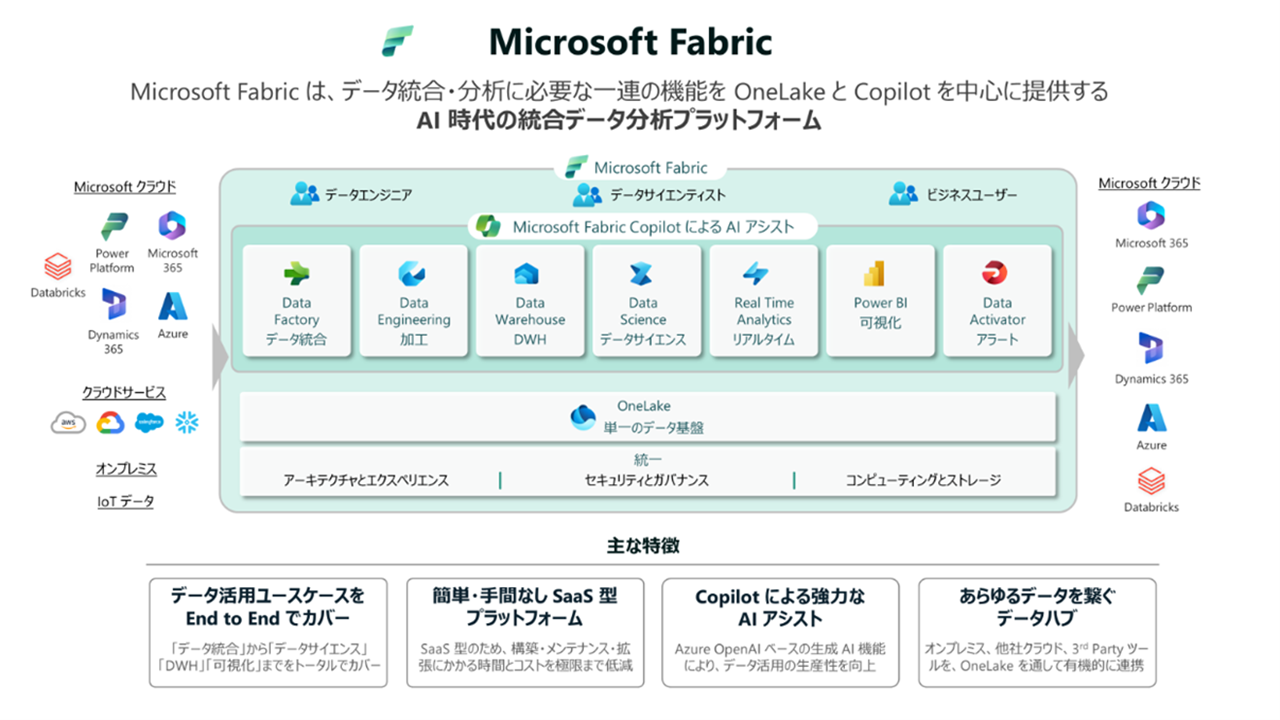
Microsoft Fabricの概念図(出典:日本マイクロソフト株式会社)
まとめ
本記事では、データレイクの必要性とデータ分析基盤の構成要素、最新のデータ分析基盤サービスであるMicrosoft Fabricについてお話しさせていただきました。電通総研は、Fabricをはじめとするデータ分析基盤について、マルチベンダー・マルチクラウドでのシステム構築に取り組んでおり、お客様のご要件やクラウド利用状況に応じたインプリメンテーションが可能です。データ分析基盤やデータ活用全般についての課題をお持ちでしたら、是非お声掛けください。本記事が、皆様のデータ分析基盤に関する理解を深め、電通総研にご興味をお持ちいただくきっかけとなりましたら嬉しく思います。
本記事は役に立ちましたか?コメント・問合せも承ります。